- Home
- Fraud Detection and Risk Analysis with Data Science Services
Fraud Detection and Risk Analysis with Data Science Services
June 18, 2025 - Blog
Fraud Detection and Risk Analysis with Data Science Services
In the digital age, businesses face growing threats from fraudulent activities and operational risks that can lead to serious financial, reputational, and legal consequences. From identity theft in fintech to false insurance claims, cyberattacks, and transaction fraud, the volume and complexity of threats have increased dramatically.
Traditional rule-based systems are no longer sufficient to keep up with evolving fraudulent behavior. That’s where data science services come in — offering smarter, scalable, and adaptive solutions that enable businesses to detect and mitigate risks in real time.
This blog explores how data science transforms fraud detection and risk analysis, the techniques used, real-world applications, and how Code Driven Labs supports companies in building robust, AI-powered systems tailored to their needs.
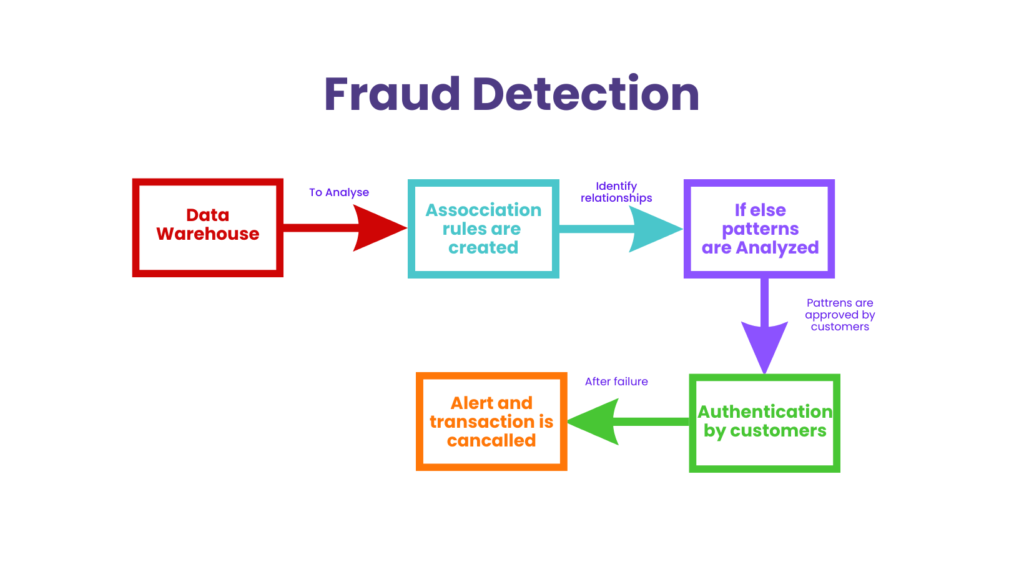
Why Traditional Fraud Detection Methods Fall Short
Traditional fraud detection systems rely heavily on static rules and manual oversight. While these methods work for known patterns, they fail to identify new and complex fraudulent activities, such as:
-
Synthetic identity fraud
-
Sophisticated phishing attacks
-
Insider threats
-
Real-time financial manipulations
-
Application fraud in lending or insurance
Manual systems are slow, labor-intensive, and prone to human error. They also generate a high rate of false positives, causing inconvenience to customers and operational inefficiencies.
Modern fraudsters adapt quickly. Businesses need intelligent, predictive systems that learn from data, detect anomalies, and adapt continuously — and that’s where data science plays a critical role.
The Role of Data Science in Fraud Detection and Risk Analysis
Data science leverages statistical models, machine learning (ML), and big data analytics to identify patterns, predict behavior, and detect anomalies that may indicate fraudulent or high-risk activity. Here’s how it works across different use cases.
1. Fraud Detection
Data science models analyze vast volumes of transactional and behavioral data to identify signs of fraud in:
-
Banking and Fintech: Credit card fraud, account takeover, phishing, synthetic identity fraud
-
Insurance: Fake claims, duplicate claims, staged accidents
-
Retail and eCommerce: Fake returns, promo code abuse, payment fraud
-
Healthcare: Billing fraud, identity misuse, unnecessary procedures
Key Techniques Used:
-
Anomaly Detection: Flags unusual activity outside normal patterns, such as large withdrawals, high-frequency purchases, or login attempts from unknown locations.
-
Supervised Learning Models: Algorithms such as logistic regression, decision trees, and XGBoost trained on labeled fraudulent and non-fraudulent data.
-
Unsupervised Learning: Clustering and dimensionality reduction techniques (like K-means or PCA) to detect unknown fraud patterns.
-
Neural Networks: Deep learning models for complex pattern recognition in large-scale data environments.
-
Real-time Scoring Systems: ML-powered decision engines that assign fraud probability scores during transaction processing.
2. Risk Analysis
Risk analysis assesses the likelihood and impact of potential events, helping businesses prevent losses and make informed decisions.
Applications Include:
-
Credit Risk Scoring: Predicting loan default probability using behavioral and demographic data.
-
Operational Risk Management: Analyzing system logs, employee behavior, and internal processes for early warnings.
-
Cybersecurity Risk: Detecting vulnerabilities and breach attempts using network traffic analysis and behavioral modeling.
-
Supply Chain Risk: Forecasting delays, failures, or fraud in procurement and logistics networks.
Techniques Used:
-
Predictive Modeling: Using regression, classification, or ensemble models to forecast risks.
-
Monte Carlo Simulation: Simulating multiple scenarios to assess risk distribution.
-
Text Mining & NLP: Extracting risk-related information from contracts, emails, and unstructured data sources.
-
Bayesian Networks: Probabilistic models that provide insight into uncertain risk variables and dependencies.
Benefits of Using Data Science for Fraud and Risk Management
-
Proactive Risk Mitigation: Predict threats before they occur.
-
Real-Time Detection: Analyze activity and transactions instantly.
-
Lower False Positives: Reduce customer inconvenience and operational costs.
-
Scalability: Handle massive volumes of data efficiently.
-
Improved Compliance: Stay aligned with regulations like AML, GDPR, and PCI-DSS.
-
Continuous Learning: Adaptive systems that improve accuracy over time.
Real-World Examples
Example 1: Credit Card Fraud Detection
A leading financial institution used machine learning models to analyze thousands of variables from transaction data, including location, device, time, and historical patterns. The system flagged anomalous transactions in real time and sent them for review. As a result:
-
Fraud loss dropped by 45%
-
False positives reduced by 60%
-
Response time improved from hours to seconds
Example 2: Insurance Claim Verification
An insurance company implemented a risk scoring system using data science to detect fraudulent motor insurance claims. The model flagged claims with high-risk scores based on accident patterns, claimant history, and vehicle data.
-
Fraudulent claims decreased by 38%
-
Investigations became more focused and effective
Challenges in Implementing Fraud and Risk Models
Despite the benefits, implementing fraud detection systems using data science comes with challenges:
-
Data Quality and Integration: Inconsistent, siloed, or incomplete data sources.
-
Model Explainability: Especially important in regulated industries (e.g., finance or healthcare).
-
Scalability and Latency: Need for real-time processing of large data volumes.
-
Model Drift: Patterns of fraud and risk evolve, requiring regular retraining.
-
Security and Compliance: Ensuring sensitive data is processed securely and within legal frameworks.
How Code Driven Labs Helps Businesses Build Robust Fraud and Risk Systems
At Code Driven Labs, we specialize in helping companies across sectors implement advanced fraud detection and risk analysis systems using data science, without the complexity of building in-house teams or infrastructure.
Here’s how we help:
1. Consultation and Strategy
We begin by understanding your business model, data environment, and specific risk exposure. Based on this, we design a data science strategy tailored to your use case.
2. Data Infrastructure and Integration
We connect and clean your structured and unstructured data from multiple sources — transactions, CRM, ERP, emails, network logs, etc. — into a secure and centralized pipeline.
3. Model Development and Testing
Using cutting-edge algorithms, we build, validate, and fine-tune models for fraud detection, credit scoring, risk prediction, or anomaly detection. Our models are trained to detect both known and emerging fraud patterns.
4. Real-Time Decision Engines
We implement real-time risk scoring systems using APIs, microservices, or cloud platforms. These solutions can integrate directly into your transaction processing or claim validation systems.
5. Dashboards and Monitoring Tools
We deliver intuitive dashboards for your teams to track alerts, investigate flagged cases, and monitor fraud trends — all with role-based access and audit trails.
6. Compliance and Explainability
Our models are designed to meet industry regulations and provide explainable results, essential for internal audits, regulatory compliance, and business confidence.
7. Continuous Learning and Support
We don’t just deliver and leave. We help you maintain, retrain, and evolve your models as fraud tactics change or new data becomes available.

Why Choose Code Driven Labs?
-
Domain Experience: Deep expertise in finance, insurance, eCommerce, and healthcare fraud.
-
AI-Powered and Scalable: We build AI-first solutions designed to grow with your business.
-
Speed to Value: Quick deployment cycles and ready-to-integrate architectures.
-
Custom Solutions: We don’t sell pre-packaged tools. Every solution is customized.
-
End-to-End Support: From data acquisition to production deployment and beyond.
Conclusion
Fraud and risk management are no longer just concerns for large enterprises. With the rise of digital transactions, automation, and remote access, even small and mid-sized businesses face growing threats. Implementing intelligent, data-driven systems for fraud detection and risk analysis is now essential for sustainability and growth.
By leveraging data science, businesses can detect fraud in real time, reduce financial losses, improve compliance, and build trust with customers and partners. And with the right partner — like Code Driven Labs — you don’t have to do it alone.
We help you build, deploy, and maintain advanced fraud detection and risk analytics systems that deliver immediate, measurable impact without massive internal investment.